What is Timsort?
Understanding probably one of the most commonly used sorting algorithms.
We all have used the array.sort() and sorted() functions in python, haven’t we? C’mon, we all have used it to save time! But have we ever tried to understand what algorithm is being executed in the background? In my quest to find out and understand the underlying algorithm, I came across an article on Wikipedia about Timsort.
Timsort, named after its inventor Tim Peters, has been the default sorting algorithm Python since version 2.3! Despite all this, Timsort is still a very obscure sort. Still, many students and engineers are unaware of this sort and how it works! So let’s try and understand how this algorithm works.
Timsort and its History

Tim came up with this sorting algorithm in the year 2002 after realising that real-world data almost always contain blocks that are already sorted, either in the ascending order or the descending order. This was something that other sorting algorithms didn’t take into consideration. So his approach of sorting was to identify such blocks in the given dataset called runs and sort them further using Mergesort and Binary Insertion Sort.
But why Timsort?
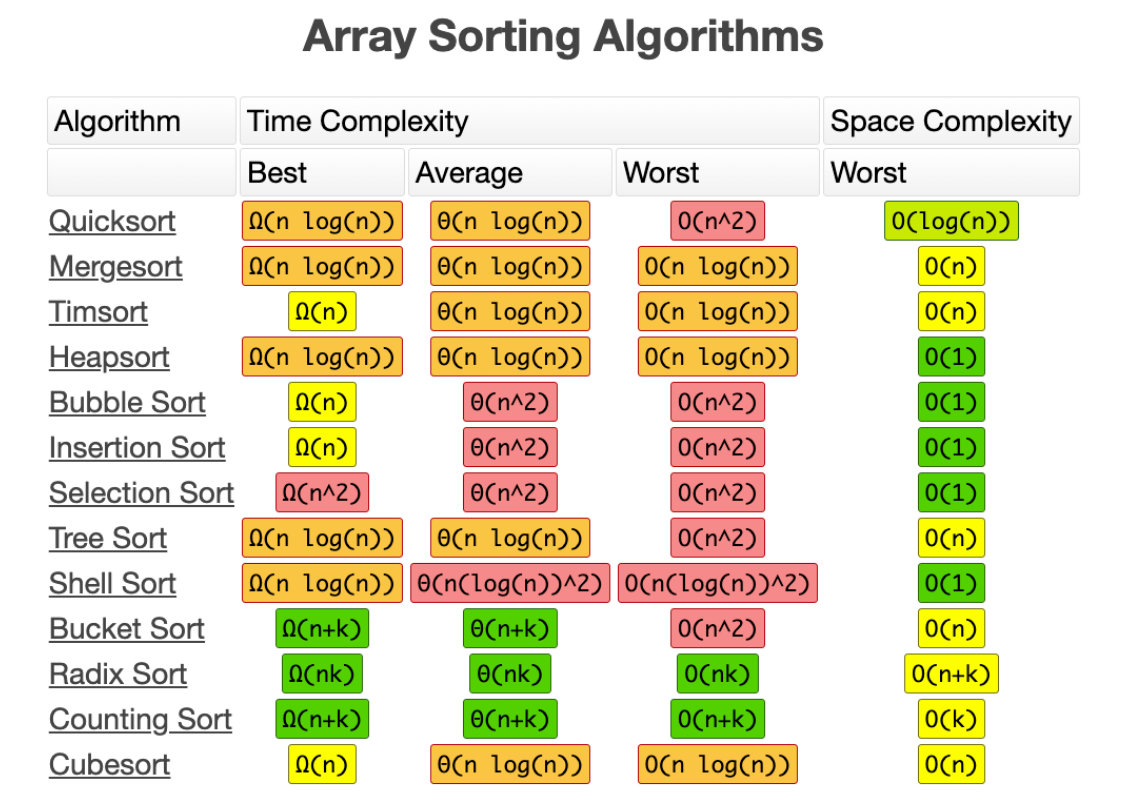
After looking at the above table one might argue that Quicksort and Merge Sort both have the same average time complexity as Timsort, then what’s the need for Timsort? To begin with, if we take a look at the best time complexity, Timsort outperforms both, Quicksort and Mergesort. Not only that, at its worst, although it runs at a speed similar to that of Mergesort, it outperforms Quicksort!
Note: Quicksort is efficient for very large datasets but not for small datasets.
Okay, enough about time complexity. If we talk in terms of space complexity, Timsort has a complexity of O(n), which when compared to other algorithms like Quicksort that have a complexity O(1), suggests that maybe it lies on the more inadequate side of the spectrum.
Another criterion on which sorting algorithms are generally assessed is stability. What is stability? A sorting algorithm is said to be stable in nature when elements of the same value maintain their original order even after sorting. It is often required while sorting real-world data like sorting entries of names in a school-record etc.
When compared on paper, Heapsort also seems to be better than Timsort. It is an in-place sorting algorithm, has similar average and worst-case time complexities compared to Timsort, then why is Timsort still preferred as the default sorting algorithm? It is because Heapsort has a poor locality of reference. The operating system cannot predict the pointer’s next position as the pointer can either multiply or divide by 2.
Understanding Timsort
Timsort is a hybrid and adaptive algorithm. It uses both Binary Insertion Sort and Merge Sort to sort a list in an average time of O(n logn) but in the best case, it can sort the given dataset in O(n) time. It identifies already sorted chunks of the list first and uses these chunks to sort the remainder more efficiently.
Implementing Timsort
Implementing Timsort is a little difficult, and understanding it also is a little complex. To make it easier for me and you, let’s break down Timsort into 3 steps
1. Checking List Size
While checking the size of the list if we find that the size of the list is less than 64 elements, Timsort will directly apply Binary Insertion Sort. But what’s the use of learning about a new sort if we're going to just apply an Insertion sort you might ask! Yes yes, we are discussing Timsort but, it has been found that Binary Insertion Sort or Insertion Sort, in general, is highly efficient and fast on a list whose size is in the range of 23–64 elements but quite slow on lights or larger size.
Binary Insertion Sort
Let’s take a look at a variation of Insertion Sort, called Binary Insertion Sort.

In Binary Insertion Sort, we use the normal binary search to find the correct index in the sorted section of the list to insert the selected unsorted element at each iteration, unlike the standard Insertion Sort that uses linear search to do the same. Further, the normal Insertion Sorting takes O(n) comparisons in the worst case, but this is reduced to O(n logn) when Binary Insertion Sort is used.
But what do we do if the size of the list is more than 64 elements? Simple, we move onto Step 2.
2. Finding Runs in the List
What are runs? In simple terms, they are blocks of the given list. A natural run is a block of the list in which all the elements are either strictly increasing or decreasing. We look for such runs in the list because we don’t have to sort them. The increasing runs can be simply merged with the next run but the decreasing runs are first blindly reversed, then merged with the next run.

I hate to break it to you, but everything isn’t so straightforward. During the first pass of the list, the algorithm while looking for runs also calculates the minimum run size and this is given the term minrun. The algorithm chooses the value of minrun from the range of 32–64 inclusive because Binary Insertion Sort is faster in lists of smaller size.

Furthermore, the value of minrun is generally equal to or nearly less than a power of 2, because merging lists of such size is more efficient. We’ll look more into it while learning about the implementation of Timsort.
3.a Merging the Sorted Runs
After finding runs in the list that are of size greater than or equal to minrun, Timsort moves on to perform Merge Sort on these sorted runs. However, Timsort has to maintain stability while merging the runs.

To ensure that the algorithm is stable, Timsort as when it finds a run in the list, it adds that run into a stack.

During merging, the Timsort has to balance two competing needs. First, we would have to delay the merging process as much as possible so that we can exploit patterns that might come up later in the list. But at the same time, merging the runs as soon as possible to exploit the run just found, which is still high in the memory hierarchy.
To balance these two things out, unlike a normal stack where only the top entries are considered, Timsort considers the top three entries (runs) in the stack. And in doing so, creates two rules that must hold of those items:
- A > B + C
- B > C
Now the Merge Sort that is followed to merge two runs in Timsort is again, yes, you guessed it right, a variation of the general Merge Sort called In-place Merge Sort. It is also because merging two adjacent runs of different lengths and maintaining their stability is hard. In In-place Merge Sort, instead of making a new list of size n+m (assuming that n and m are the sizes of the two runs), a temporary copy of the smaller list (say n < m) is made and the larger run is shifted by n places.
3.b Galloping

Timsort has another optimisation in the form of Galloping. If the algorithm finds that if one of the two runs is “winning” continuously for some time then instead of pushing elements one by one, it pushes elements as a chunk.

Consider the above two lists. We notice that elements from A[0:4] are all smaller than B[1], so checking for each element will be very inefficient. So when Timsort enters into galloping mode, if binary searches for the position where B[1] can fit in list A. This way the algorithm can move the entire chunk of A[0:4] into place. Then the algorithm binary searches for the correct position of A[0] in B.
But it has been noticed that galloping is not worth it if the correct position for B[0] is very close to the beginning of A (or vice versa), so if that is the case then the algorithm exits gallop mode quickly. Also, the algorithm only enters galloping mode after a certain number of consecutive A-only or B-only wins.
Conclusion
Timsort is a very fast and stable sort, but more importantly, it is optimised or rather should I say it is designed with keeping the real-world data sets in mind. Are there faster and better sorting algorithms? Probably yes. Can Timsort be used in every situation? Maybe not. But in the end, it is an optimised approach to solving a few dataset problems.
Even after all this research I still believe there is so much more to this sorting algorithm that I haven’t figured out yet!
